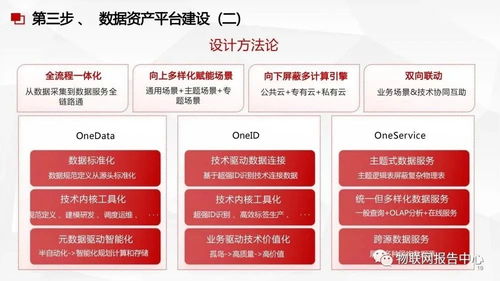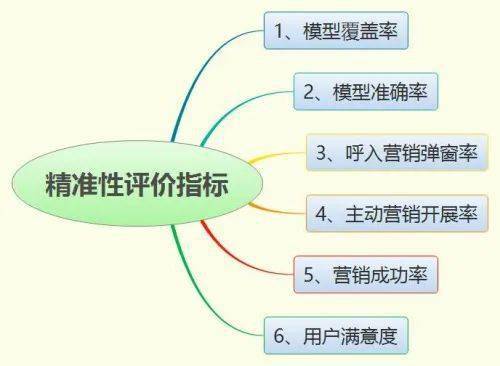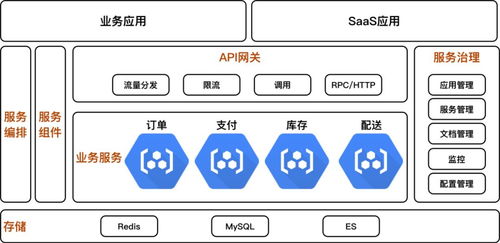
作為一名深耕技術一線的程序員,數據中臺對我而言,不僅僅是企業數據戰略的抽象概念,更是實實在在的技術架構與工程實踐。在數據中臺的眾多服務模塊中,數據處理服務無疑是核心環節之一,它直接決定了數據從原始狀態到可用資產的質量與效率。
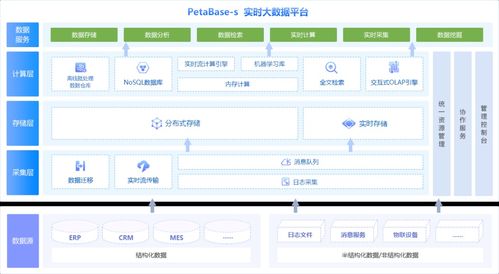
數據處理服務,顧名思義,是指數據中臺提供的對原始數據進行清洗、轉換、集成、加工等處理的能力。在數據中臺架構下,數據處理服務通常依托于統一的數據處理引擎和調度平臺,例如基于 Spark、Flink 等大數據計算框架,或通過 Airflow、DolphinScheduler 等調度工具實現任務編排。其核心價值在于將分散、異構的數據源進行標準化處理,輸出結構統一、質量可信的數據集,供上層數據應用消費。
從程序員的角度,數據處理服務的設計應關注以下幾個關鍵點:
- 可擴展性與性能:面對海量數據,數據處理服務必須能夠水平擴展,支持分布式計算。程序員在開發數據處理任務時,需考慮數據分區、并行計算、內存優化等技術手段,確保處理任務在高并發、大數據量場景下依然穩定高效。
- 數據質量與一致性:數據處理過程中,數據清洗、去重、格式校驗等環節必不可少。程序員需要設計健壯的異常處理機制和數據校驗規則,防止臟數據流入下游,同時通過事務或冪等設計保證數據處理任務的可重入性和數據一致性。
- 配置化與低代碼:為了提升數據開發的效率,數據處理服務應支持配置化的任務定義。例如,通過 SQL 或可視化界面配置數據轉換邏輯,減少硬編碼,降低開發門檻。這對于快速響應業務需求變化尤為重要。
- 監控與運維:作為生產級服務,數據處理任務需要有完善的監控告警體系。程序員應集成日志采集、指標上報、任務依賴可視化等功能,便于實時追蹤任務狀態、定位故障,并通過自動化運維工具實現任務的彈性伸縮與故障自愈。
在實際項目中,數據處理服務常以微服務或平臺化方式提供。例如,企業可能構建一個統一的數據開發平臺,集成任務調度、資源管理、數據血緣等功能,讓數據工程師可以像搭積木一樣組合數據處理流程。隨著云原生技術的普及,容器化、Serverless 架構正逐漸成為數據處理服務的新趨勢,進一步提升資源利用率和部署靈活性。
數據處理服務是數據中臺技術落地的關鍵支撐。程序員在參與其設計與實現時,不僅要關注技術選型與性能優化,更要站在數據資產管理的全局視角,確保數據處理流程的可靠性、可維護性與業務價值交付。唯有如此,數據中臺才能真正成為驅動企業數字化轉型的引擎。